
Recently I stumbled over SegNet, a tool which uses a convolutional decoder-encoder (type of neural net) to distinguish between 12 categories (like road, pedestrian, …) that a self-driving car might encounter. I tried this tool with several different pictures of roads and want to share the results with you. The big question is: Would I take a ride in a car controlled by this algorithm?
You can try the tool yourself with the above link but take care of two things:
- Image size: It does not say, but ~2MB seems to be the maximum size. For some images it gave me an unspecific error and after I realised that it were exactly the largest ones I decreased their size and then it worked.
- Format: Images get squeezed into horizontal format, which somehow makes sense since a car camera will not have to deal with different images, but in the beginning you might be surprised what happened to your image 😉
Contents
About SegNet
On their website they provide 3 publications about SegNet.
- Kendall et al: Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding
- Badrinarayanan et al: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- Badrinarayanan et al: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling
I read the first one (Kendall et al) in which they present a novel deep learning framework for probabilistic pixel-wise semantic segmentation called Bayesian SegNet. They also mention that they additionally model uncertainty which is quite relevant e.g. when considering self driving cars. If it predicts something is not a pedestrian it should be really sure about it. They trained and tested the algorithm on 3 different datasets, one being CamVid (road scenes) for which I will test the resulting model.
Classes
On the online tool they provide 12 classes that can be predicted.

Video analysis
On their website they provide three videos how SegNet works.
The first one shows a street scene in the upper half and how the SegNet predicts the images in the lower half. See for yourself:
A few things I noticed:
- It jumps around a lot (which means that something is a vehicle in one frame but a road in the next frame)
- It sees many cars and bikes where there are none
- When there is a bike or a car, it detects it correctly
- It really has difficulties with shadows (often predicts a pavement where there is just a shadow on the street)
My test images
For each image I defined beforehand the categories that I think should be recognised.
The easy ones
I chose a few images where a road and a car could clearly be seen and the tool should be able to categorise them.
Picture 1
Most relevant components: Road, car, road marking, tree


From the 4 components I thought were relevant all were classified correctly. The road marking on the left is interrupted though. With respect to things that are falsely classified the sign is classified as vehicle, sign and building.
Picture 2
Most relevant components: Car, road, road markings, sign symbol, tree


In this image the car, road, road markings and trees are easily reconized, even the small car in the distance. The sign symbol again is a mixture of different things and not classified correctly.
Picture 3
Most relevant components: Car, road, tree


Also in this image the car, road and trees are correct. It even recognizes the pole that I did not see as that important. It sees a little too much pavement.
Picture 4
Most relevant components: Road, tree, fence

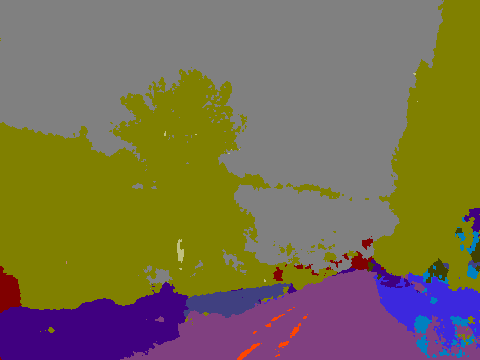
The road and the trees are mostly correct but the fence is only recognized partially. The rest of it is seen as a vehicle.
Might be difficult
Those are pics that might be difficult because the angle is not optimal (a self-driving car would hopefully not get pictures of that angle) but I hoped it would still be able to deal with them.
Picture 5
Most relevant components: Road, tree, animals(?), “pavement”
This picture is already interesting because it contains animals which is not a category and the pavement/area next to the road is full of snow.


The classification of the trees is perfect. The road is also almost correct and I am surprised that the snowy area is seen as pavement (which is correct in my opinion because there is no other category for things beside the street). I guess it is also okay that the circus tent is recognized as a building and the camels are pedestrians since there is no animal category.
Picture 6
Most relevant components: Road, car/truck, tree, “fence”/wall


The truck is a mixture of car/building but it is hard to say whether this is because of its specific form or the reflection in the windshield. The trees are perfect as in the previous images. The road is split into road and pavement, this can have two reasons: (1) The two halfs of the street look different and (2) again, the reflection in the windshield is not optimal. The wall is recognized as a building although I think fence would be more appropriate.
Picture 7
Most relevant components: Road, car, tree, pole


Car and tree are correct. Also the small car to the right is recognized. The road is again a mixture of road and pavement. The pole is also recognized pretty well.
Picture 9
Most relevant components: Car, road, tree, “fence”


Although there is a lot of rain on the window the road is recognized correctly. The car seems to be a mixture of vehicle, bike and pedestrian. The trees are correctly classified as always. I am surprised how well the “fence” is recognized although SegNet also predicts some building.
Picture 10
Most relevant components: Car, house, tree, road, “fence”, pole


Car, house, trees, road, “fence” and pole are easily recognized. The piece of the truck is seen as a building but I think that is ok with only that small piece to see.
Probably difficult
For this category I chose two pictures where the road is not easily recognizable because a self-driving car should also be able to deal with muddy and snowy roads. I chose a third picture that has an obstacle on the street because I would like to see what it makes of that.
Picture 11
Most relevant components: Road, tree, house, dog(?)


With this picture I was surprised that it recognized the road (although it’s a little bit hard to see because of the squeezing). Our dog Hari luckily is recognized as a pedestrian. The trees are also recognized but the classification of the house is a little bit fuzzy. The leaves and tractor tracks on the side of the road seem to confuse the SegNet a little bit.
Picture 12
Most relevant components: Road, house


As expected, the snow was hard to classify as street but honestly from just one picture you can’t know whether this is a road or pavement. The SegNet (or a self-driving car) would need more information than just an image to decide whether it can drive there or not. The space between the correctly classified houses is also wrongly classified as a house.
Picture 13
Most relevant components: Tractor, road, obstacle(?), person, house

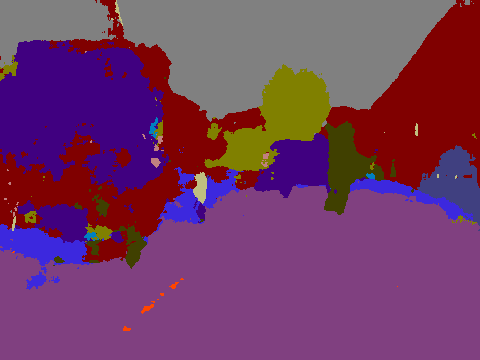
In this image I thought it would be interesting what the SegNet would do with the coals in the middle of the road. Unfortunately it does not classify them as anything that should not be used for driving. The tractor is a mixture between vehicle and house, which we have already seen with the truck above. Also the car in the background is correctly classified, as well as the trees and fortunately also the pedestrian.
Is it ready for self-driving cars?
My conclusion after these few tests is that some categories (cars, trees, sky) are recognised very well (even small cars in the distance), but some others cause difficulty (trucks and tractors a mixture of vehicle/building). I only had one pedestrian and he was recognised (which is very important in my opinion). Poles are also categorised correctly but it seems that the tool has difficulties with road signs, which could also be relevant with respect to navigation (not that important because of other means of navigation) and perceiving obstacles (more important) since road signs can give information about speed limit, right of way and hints about obstacles like construction sites. Therefore it would be necessary to not only see them but also understand their meaning.
In general it is rather promising I think and it works a lot better than expected. Also it does a great job in distinguishing between so many categories and not only yes/no (“I can drive there”/”I can not drive there”).
But for my own safety, I would not use a self-driving car with this algorithm, but it’s rather theoretical anyway. Self-driving cars, like the one from Google, have many more other information available (e.g. lots of sensors) to decide what to do, as explained by excellent answer on Quora.