
In a recent blog post I evaluated the R package lime on a regression data set. After this I wanted to go deeper (pun not intended ;)) and use lime on more complicated models such as deep neural networks. I have started collecting cat and dog pictures a long time ago with the idea in … Continue reading Tensorflow CNN and lime on my own cat & dog images
Category: Data Science
Data Science related stuff like collecting data, statistical methods, machine learning, … Mostly #rstats
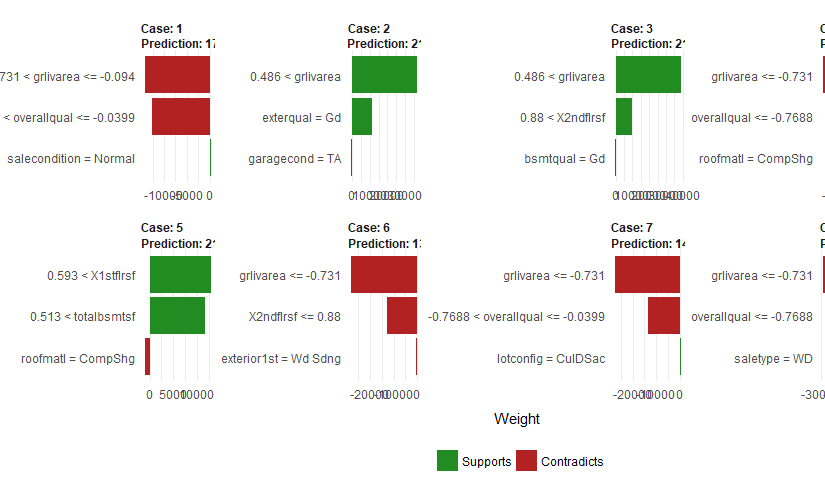
Exploring lime on the house prices dataset
Pretty recently I found a paper with the title “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. The topic of interpretability is very important in the times of complex machine learning models and it’s also related to my PhD topic (reliability of machine learning models). Therefore I wanted to play around with … Continue reading Exploring lime on the house prices dataset

Find closest date before or after event (MATLAB)
It’s the second time since I have been using MATLAB that I need to find the closest date to a given target date in an array. Of course I didn’t remember how I did it the last time and I couldn’t find a solution that suited my needs on the internet. So I decided to … Continue reading Find closest date before or after event (MATLAB)

Learning Club 16: Genetic Algorithms
Some time ago I published a blog post with the title Know your data structures!. In this previous post I explained how I improved the running time of a genetic algorithm. I promised to go more into detail about other noteworthy things in the code in a separate article since not everything was straightforward when … Continue reading Learning Club 16: Genetic Algorithms
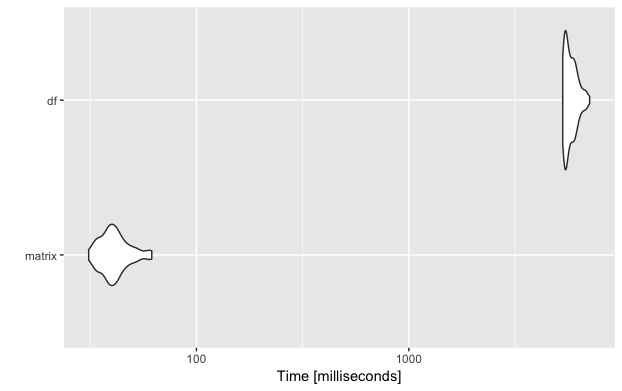
Know your data structures!
Just a few days ago I stated the following on Twitter: Just reduced the runtime of an algorithm from 9 hours to 3 min. by using a different data structure… Know you data structures 🙂 #rstats — Verena Haunschmid (@ExpectAPatronum) May 1, 2017 Since my tweet has been liked and shared a lot, I thought … Continue reading Know your data structures!
Presentation “R for Data Science”
Some weeks ago I had a presentation at my work place about “R for data science” that I’d like to share with you. I’ve written the slides in R and rmarkdown and uploaded them to rpubs.com. I chose to use rmarkdown for my slides although we have great company PowerPoint templates, because I wanted to … Continue reading Presentation “R for Data Science”

Accessing your Fitbit data
Since I am a data junkie and bought my Fitbit Charge HR mainly because I wanted to collect and analyse data about myself, I was looking for ways to download the data to my computer. For most people the great stats overview in the app and in the online dashboard will be sufficient but some … Continue reading Accessing your Fitbit data
Learning Club 05-07: Starting to love rmarkdown (Naive Bayes, Clustering, Linear Regression)
I remember when I had an R course at university I was really not a fan of rmarkdown and knitr. But since I participate in a Learning Club, where people are encouraged to document and present their code, data and results, I started to love it. Prior to that I’ve always documented my assignments at the university either … Continue reading Learning Club 05-07: Starting to love rmarkdown (Naive Bayes, Clustering, Linear Regression)
I was guest at the Becoming a Data Scientist Podcast!
Almost 2 weeks ago the Becoming a Data Scientist podcast had 4 special interviews – each of them with members of the Learning Club, including me! I was super excited when Renee asked me some weeks ago if I wanted to participate and I was a little bit nervous during the interview. But I think … Continue reading I was guest at the Becoming a Data Scientist Podcast!

Finding data sets PART 3: Weather, geographical and government data
This is the third post in my dataset series. The first part gave a more general overview on where to get data. In the second post I listed sources for sports, movies, music and books data. This section will give you information on how to get weather, public/governmental data and how to find GIS data. … Continue reading Finding data sets PART 3: Weather, geographical and government data